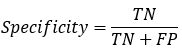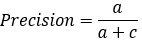|
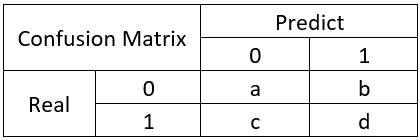
本文整理了关于机器学习分类问题的评价指标——Confusion Matrix、ROC、AUC的概念以及理解。 混淆矩阵在机器学习领域中,混淆矩阵(confusion matrix)是一种评价分类模型好坏的形象化展示工具。其中,矩阵的每一列表示的是模型预测的样本情况;矩阵的每一行表示的样本的真实情况。 举个经典的二分类例子: 混淆表格:
混淆矩阵是除了ROC曲线和AUC之外的另一个判断分类好坏程度的方法,通过混淆矩阵我们可以很清楚的看出每一类样本的识别正误情况。 混淆矩阵比模型的精度的评价指标更能够详细地反映出模型的”好坏”。模型的精度指标,在正负样本数量不均衡的情况下,会出现容易误导的结果。 基本概念【1】True Positive 真正类(TP),样本的真实类别是正类,并且模型识别的结果也是正类。 【2】False Negative 假负类(FN),样本的真实类别是正类,但是模型将其识别成为负类。 【3】False Positive 假正类(FP),样本的真实类别是负类,但是模型将其识别成为正类。 【4】True Negative 真负类(TN),样本的真实类别是负类,并且模型将其识别成为负类。 评价指标(名词翻译来自机器学习实战)【1】Accuracy(精确率) 模型的精度,即模型识别正确的个数 / 样本的总个数 。一般情况下,模型的精度越高,说明模型的效果越好。 【2*】Precision(正确率) 又称为查准率,表示在模型识别为正类的样本中,真正为正类的样本所占的比例。 一般情况下,查准率越高,说明模型的效果越好。
【3*】Recall(召回率)=Sensitivity(敏感指标,truepositive rate ,TPR) =敏感性指标=查全率,表示的是,模型正确识别出为正类的样本的数量占总的正类样本数量的比值。 一般情况下,Recall越高,说明有更多的正类样本被模型预测正确,模型的效果越好。
【4】Specificity 特异性指标,表示的是模型识别为负类的样本的数量,占总的负类样本数量的比值。 负正类率(false positive rate, FPR),计算公式为:FPR=FP/(TN+FP),计算的是模型错识别为正类的负类样本占所有负类样本的比例,一般越低越好。 Specificity = 1 - FPR 【5】Fβ_Score Fβ的物理意义就是将正确率和召回率的一种加权平均,在合并的过程中,召回率的权重是正确率的β倍。F1分数认为召回率和正确率同等重要,F2分数认为召回率的重要程度是正确率的2倍,而F0.5分数认为召回率的重要程度是正确率的一半。 比较常用的是F1分数(F1 Score),是统计学中用来衡量二分类模型精确度的一种指标。 【6】F1_Score 数学定义:F1分数(F1-Score),又称为平衡F分数(BalancedScore),它被定义为正确率和召回率的调和平均数。 β=1的情况,F1-Score的值是从0到1的,1是最好,0是最差。
回到上面二分类的例子:
那么多分类呢?
因此我们知道,计算Precision,Recall,Specificity等只是计算某一分类的特性,而Accuracy和F1-Score是判断分类模型总体的标准。 sklearn中 F1-micro 与 F1-macro区别和计算原理在sklearn中的计算F1的函数为 f1_score ,其中有一个参数average用来控制F1的计算方式,今天我们就说说当参数取micro和macro时候的区别。
详见:https://www.cnblogs.com/techengin/p/8962024.html ROC曲线ROC曲线的横坐标是前文提到的FPR(false positive rate),纵坐标是TPR(truepositive rate,召回率)。 放在具体领域来理解上述两个指标。如在医学诊断中,判断有病的样本。
不难发现,这两个指标之间是相互制约的。如果某个医生对于有病的症状比较敏感,稍微的小症状都判断为有病,那么他的第一个指标应该会很高,但是第二个指标也就相应地变高。最极端的情况下,他把所有的样本都看做有病,那么第一个指标达到1,第二个指标也为1。
我们可以看出
为什么使用ROC曲线既然已经这么多评价标准,为什么还要使用ROC和AUC呢? 因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。 AUC值AUC(Area Under Curve)被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
计算AUC:
|
|
|