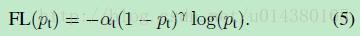|
https://zhuanlan.zhihu.com/p/38193873 https://www.cnblogs.com/makefile/p/YOLOv3.html 让我们再看一下滑动窗口检测器。我们可以通过在特征图上滑动窗口来检测目标。对于 不同的目标类型,我们使用不同的窗口类型。以前的滑动窗口方法的致命错误在于使用窗口作 为最终的边界框,这就需要非常多的形状来覆盖大部分目标。更有效的方法是将窗口当做初始 猜想,这样我们就得到了从当前滑动窗口同时预测类别和边界框的检测器。 单次检测器通常需要在准确率和实时处理速度之间进行权衡。它们在检测太近距离或太小 的目标时容易出现问题。 Faster R-CNN速度上并不能满足实时的要求。YOLO这类方法使用了回归的思想,既给定输入图像,直接在图像的多个位置上回归出这个位置附近的目标位置和目标类别。 (1.1)YOLOv1 (CVPR2016, oral) 检测流程: 1.给定一个输入图像,首先将图像分割成7*7的网格 2.对于每个网格,都负责预测2个边框(包括每个边框的位置,目标物体置信度和多个类别上的概率) 3.根据上一步可以预测7*7*2个目标窗口,根据阈值去除执行度比较低的目标窗口,最后NMS去除冗余窗口 优点:YOLO将目标检测任务转换成回归问题,大大加快了检测的速度。同时由于网络预测每个目标窗口时使用的是全局信息,使得false positive比例大幅降低(充分的上下文信息)。 存在的问题:使用整图特征在7*7的粗糙网格内回归,对目标的定位并不是很精准,检测精度不高 输入尺寸固定:由于输出层为全连接层,因此在检测时,YOLO训练模型只支持与训练图像相同的输入分辨率。其它分辨率需要缩放成改分辨率. 占比较小的目标检测效果不好.虽然每个格子可以预测B个bounding box,但是最终只选择只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。 (1.2)YOLOv2 (CVPR2016, oral) 它并没有使用多尺度特征图来做独立的检测。相反,它将特征图部分平滑化,并将其和另一个较低分辨率的特征图拼接。例如,YOLO 将一个 28 × 28 × 512 的层重塑为 14 × 14 × 2048,然后将它和 14 × 14 ×1024 的特征图拼接。之后,YOLO 在新的 14 × 14 × 3072 层上应用卷积核进行预测。 YOLO(v2)做出了很多实现上的改进,将 mAP 值从第一次发布时的 63.4 提高到了 78.6。 YOLO与Fast R-CNN相比有较大的定位误差,与基于region proposal的方法相比具有较低的召回率。因此YOLO v2主要改进是提高召回率和定位能力。下面是改进之处: Batch Normalization: v1中也大量用了Batch Normalization,同时在定位层后边用了dropout,v2中取消了dropout,在卷积层全部使用Batch Normalization。 高分辨率分类器:v1中使用224 × 224训练分类器网络,扩大到448用于检测网络。v2将ImageNet以448×448 的分辨率微调最初的分类网络,迭代10 epochs。 Anchor Boxes:v1中直接在卷积层之后使用全连接层预测bbox的坐标。v2借鉴Faster R-CNN的思想预测bbox的偏移.移除了全连接层,并且删掉了一个pooling层使特征的分辨率更大一些.另外调整了网络的输入(448->416)以使得位置坐标是奇数只有一个中心点(yolo使用pooling来下采样,有5个size=2,stride=2的max pooling,而卷积层没有降低大小,因此最后的特征是416/(2^5)=13).v1中每张图片预测7x7x2=98个box,而v2加上Anchor Boxes能预测超过1000个.检测结果从69.5mAP,81% recall变为69.2 mAP,88% recall. YOLO v2对Faster R-CNN的手选先验框方法做了改进,采样k-means在训练集bbox上进行聚类产生合适的先验框.由于使用欧氏距离会使较大的bbox比小的bbox产生更大的误差,而IOU与bbox尺寸无关,因此使用IOU参与距离计算,使得通过这些anchor boxes获得好的IOU分值。距离公式: D(box,centroid)=1−IOU(box,centroid) D(box,centroid)=1−IOU(box,centroid) 使用聚类进行选择的优势是达到相同的IOU结果时所需的anchor box数量更少,使得模型的表示能力更强,任务更容易学习.k-means算法代码实现参考:k_means_yolo.py.算法过程是:将每个bbox的宽和高相对整张图片的比例(wr,hr)进行聚类,得到k个anchor box,由于darknet代码需要配置文件中region层的anchors参数是绝对值大小,因此需要将这个比例值乘上卷积层的输出特征的大小.如输入是416x416,那么最后卷积层的特征是13x13. 细粒度特征(fine grain features):在Faster R-CNN 和 SSD 均使用了不同的feature map以适应不同尺度大小的目标.YOLOv2使用了一种不同的方法,简单添加一个 pass through layer,把浅层特征图(26x26)连接到深层特征图(连接到新加入的三个卷积核尺寸为3 * 3的卷积层最后一层的输入)。 通过叠加浅层特征图相邻特征到不同通道(而非空间位置),类似于Resnet中的identity mapping。这个方法把26x26x512的特征图叠加成13x13x2048的特征图,与原生的深层特征图相连接,使模型有了细粒度特征。此方法使得模型的性能获得了1%的提升。 Multi-Scale Training: 和YOLOv1训练时网络输入的图像尺寸固定不变不同,YOLOv2(在cfg文件中random=1时)每隔几次迭代后就会微调网络的输入尺寸。训练时每迭代10次,就会随机选择新的输入图像尺寸。因为YOLOv2的网络使用的downsamples倍率为32,所以使用32的倍数调整输入图像尺寸{320,352,…,608}。训练使用的最小的图像尺寸为320 x 320,最大的图像尺寸为608 x 608。 这使得网络可以适应多种不同尺度的输入. YOLOv2提出了一种新的分类模型Darknet-19.借鉴了很多其它网络的设计概念.主要使用3x3卷积并在pooling之后channel数加倍(VGG);global average pooling替代全连接做预测分类,并在3x3卷积之间使用1x1卷积压缩特征表示(Network in Network);使用 batch normalization 来提高稳定性,加速收敛,对模型正则化. (1.3)YOLOv3 (CVPR2016, oral) 改进之处:
分类器-类别预测: YOLOv3不使用Softmax对每个框进行分类,主要考虑因素有两个: Softmax使得每个框分配一个类别(score最大的一个),而对于Open Images这种数据集,目标可能有重叠的类别标签,因此Softmax不适用于多标签分类。 多尺度预测 每种尺度预测3个box, anchor的设计方式仍然使用聚类,得到9个聚类中心,将其按照大小均分给3中尺度. 尺度1: 在基础网络之后添加一些卷积层再输出box信息. 尺度2: 从尺度1中的倒数第二层的卷积层上采样(x2)再与最后一个16x16大小的特征图相加,再次通过多个卷积后输出box信息.相比尺度1变大两倍. 尺度3: 与尺度2类似,使用了32x32大小的特征图. YOLOv3 使用了更加复杂的骨干网络来提取特征。DarkNet-53 主要由 3 × 3 和 1× 1 的卷积核以及类似 ResNet 中的跳过连接构成。相比 ResNet-152,DarkNet 有更低的 BFLOP(十亿次浮点数运算),但能以 2 倍的速度得到相同的分类准确率。 YOLOv3 还添加了特征金字塔,以更好地检测小目标。以下是不同检测器的准确率和速度的权衡。  优点 快速,pipline简单. 背景误检率低。 通用性强。YOLO对于艺术类作品中的物体检测同样适用。它对非自然图像物体的检测率远远高于DPM和RCNN系列检测方法。 YOLO具有以下缺点: 识别物体位置精准性差。 召回率低。在每个网格中预测固定数量的bbox这种约束方式减少了候选框的数量。 (2)SSD SSD 是使用 VGG19 网络作为特征提取器(和 Faster R-CNN 中使用的 CNN 一样)的单次检测器。我们在该网络之后添加自定义卷积层(蓝色),并使用卷积核(绿色)执行预测。
然而,卷积层降低了空间维度和分辨率。因此上述模型仅可以检测较大的目标。为了解决该问题,我们从多个特征图上执行独立的目标检测。采用多尺度特征图独立检测。
SSD 使用卷积网络中较深的层来检测目标。如果我们按接近真实的比例重绘上图,我们会发现图像的空间分辨率已经被显著降低,且可能已无法定位在低分辨率中难以检测的小目标。如果出现了这样的问题,我们需要增加输入图像的分辨率。 SSD结合YOLO的回归思想以及Faster R-CNN的anchor机制实现了精准定位。YOLO预测某个位置使用的是全图的特征,SSD预测某个位置使用的是这个位置周围的特征。 建立某个位置和其特征的对应关系使用Faster R-CNN的anchor机制。 SSD 通过多个特征图完成检测。但是,最底层不会被选择执行目标检测。它们的分辨率高但是语义值不够,导致速度显著下降而不能被使用。SSD 只使用较上层执行目标检测,因此对于小的物体的检测性能较差。 (3)特征金字塔网络(FPN) 检测不同尺度的目标很有挑战性,尤其是小目标的检测。特征金字塔网络(FPN)是一种旨在提高准确率和速度的特征提取器。它取代了检测器(如 Faster R-CNN)中的特征提取器,并生成更高质量的特征图金字塔。
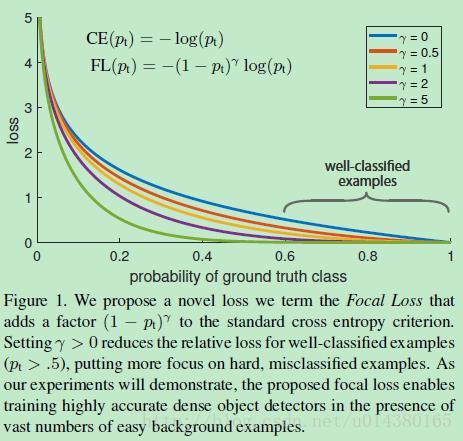
FPN 由自下而上和自上而下路径组成。其中自下而上的路径是用于特征提取的常用卷积网络。空间分辨率自下而上地下降。当检测到更高层的结构,每层的语义值增加。 虽然该重建层的语义较强,但在经过所有的上采样和下采样之后,目标的位置不精确。在重建层和相应的特征图之间添加横向连接可以使位置侦测更加准确。 (4)Focal Loss(RetinaNet) one-stage detector的准确率不如two-stage detector的原因,作者认为原因是:样本的类别不均衡导致的。我们知道在object detection领域,一张图像可能生成成千上万的candidate locations,但是其中只有很少一部分是包含object的,这就带来了类别不均衡。(1) training is inefficient as most locations are easy negatives that contribute no useful learning signal; (2) en masse, the easy negatives can overwhelm training and lead to degenerate models. 什么意思呢?负样本数量太大,占总的loss的大部分,而且多是容易分类的,因此使得模型的优化方向并不是我们所希望的那样。首先pt的范围是0到1,所以不管γ是多少,这个调制系数都是大于等于0的。易分类的样本再多,你的权重很小,那么对于total loss的共享也就不会太大。那么怎么控制样本权重呢?举个例子,假设一个二分类,样本x1属于类别1的pt=0.9,样本x2属于类别1的pt=0.6,显然前者更可能是类别1,假设γ=1,那么对于pt=0.9,调制系数则为0.1;对于pt=0.6,调制系数则为0.4,这个调制系数就是这个样本对loss的贡献程度,也就是权重,所以难分的样本(pt=0.6)的权重更大。Figure1中γ=0的蓝色曲线就是标准的交叉熵损失。 focal loss的含义可以看如下Figure1,横坐标是pt,纵坐标是loss。CE(pt)表示标准的交叉熵公式,FL(pt)表示focal loss中用到的改进的交叉熵,可以看出和原来的交叉熵对比多了一个调制系数(modulating factor)。为什么要加上这个调制系数呢?目的是通过减少易分类样本的权重,从而使得模型在训练时更专注于难分类的样本。 这里介绍下focal loss的两个重要性质:1、当一个样本被分错的时候,pt是很小的(请结合公式2,比如当y=1时,p要小于0.5才是错分类,此时pt就比较小,反之亦然),因此调制系数就趋于1,也就是说相比原来的loss是没有什么大的改变的。当pt趋于1的时候(此时分类正确而且是易分类样本),调制系数趋于0,也就是对于总的loss的贡献很小。2、当γ=0的时候,focal loss就是传统的交叉熵损失,当γ增加的时候,调制系数也会增加。 既能调整正负样本的权重,又能控制难易分类样本的权重: 实验中a的选择范围也很广,一般而言当γ增加的时候,a需要减小一点(实验中γ=2,a=0.25的效果最好) 类别不平衡会损害性能。SSD 在训练期间重新采样目标类和背景类的比率,这样它就不会被图像背景淹没。Focal loss(FL)采用另一种方法来减少训练良好的类的损失。因此,只要该模型能够很好地检测背景,就可以减少其损失并重新增强对目标类的训练。我们从交叉熵损失 CE 开始,并添加一个权重来降低高可信度类的 CE。
(4)G-CNN(CVPR2016) Region proposal方法考虑数以万计的潜在框来进行目标位置搜索,这种方式存在的问题是负样本空间大,因此需要一定的策略来进行抑制(OHEM还是region proposal方法,其本质都是一种抑制负样本的工作)。G-CNN初始化时将图像进行划分(有交叠),产生少量的框(大约180个),通过一次回归之后得到更接近物体的位置。然后以回归之后的框作为原始窗口,不断的迭代回归调整,得到最终的检测结果。 OHEM(online hard example mining),OHEM的主要思想可以用原文的一句话概括:In OHEM each example is scored by its loss, non-maximum suppression (nms) is then applied, and a minibatch is constructed with the highest-loss examples。OHEM算法虽然增加了错分类样本的权重,但是OHEM算法忽略了容易分类的样本。 |
|
|
来自: Behindrain > 《目标检测》